Herbal Remedy Review Analysis
The Challenge
Researchers at CESC wanted to publish findings on the therapeutic effects of herbal remedies for conditions including pain, anxiety, stress, and allergies. They had identified a publicly available dataset of approximately 100,000 user reviews covering 1,000 different botanical preparations, but lacked the NLP expertise to extract meaningful patterns from unstructured text data.
The fundamental question: could this dataset support publishable research on therapeutic effects, or were the data quality and structure insufficient for rigorous analysis?
Data Assessment and Quality Diagnosis
Initial examination revealed significant data quality challenges that threatened the viability of the entire research project:
- Individual reviews were extremely short, averaging only a few sentences
- Heavy use of slang and non-standard terminology made standard NLP approaches problematic
- Sparse data per botanical variety - approximately 95 reviews per preparation, insufficient for robust individual analysis
- Highly variable review quality and information content
Conducted research on NLP approaches suitable for short-form user-generated content and evaluated whether the available data could produce statistically meaningful results. The core problem: individual reviews contained too little text for topic modeling to identify coherent themes, while the slang and terminology variations created noise that would obscure legitimate patterns.
Strategic Aggregation Approach
To address the fundamental data sparsity issue, I designed an aggregation strategy: combine all reviews for each botanical preparation into composite documents. This approach transformed the corpus from 100,000 sparse, noisy individual reviews into approximately 1,000 substantive documents, each representing the collective user experience for a specific herbal remedy.
Worked with the research team to explain why individual reviews were insufficient for topic modeling and how aggregation would enable pattern discovery while maintaining the ability to analyze therapeutic effects by botanical variety. The researchers understood that this approach traded individual-level granularity for the statistical power necessary to identify meaningful themes.
This decision was critical: without aggregation, the analysis would have failed to produce interpretable results. With aggregation, the data became viable for publication-quality research.
Analytical Methodology
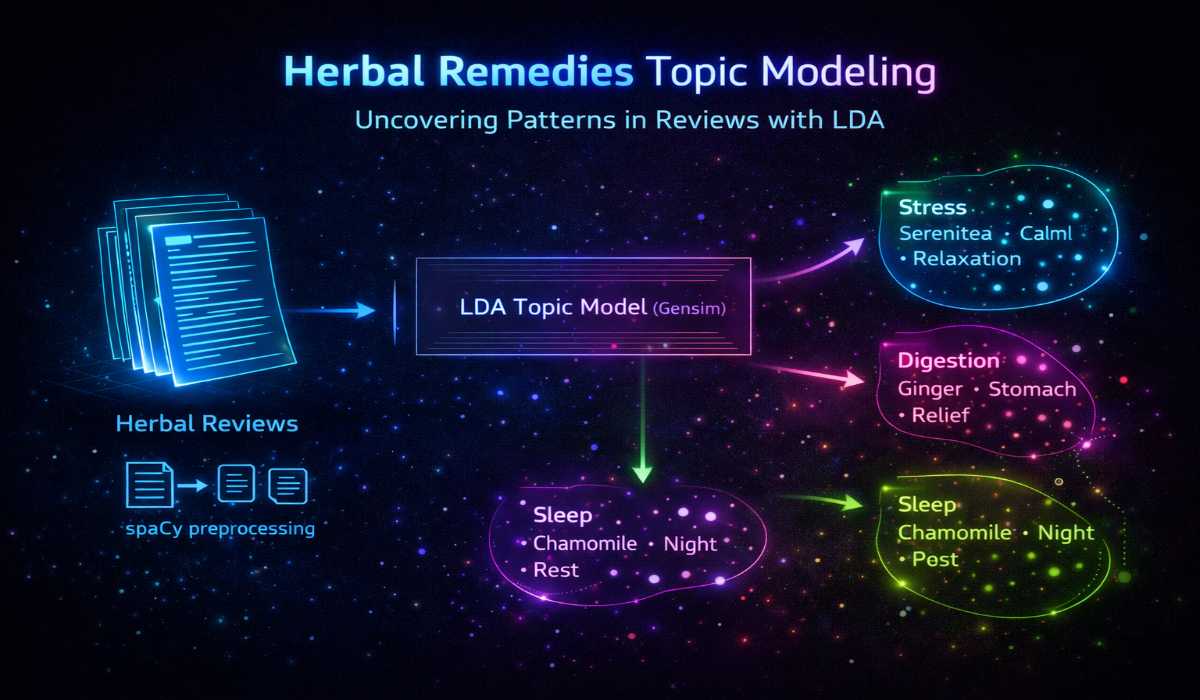
Selected Latent Dirichlet Allocation as the topic modeling approach based on research indicating it was the most suitable method for discovering latent themes in aggregated review text. Implemented a comprehensive preprocessing pipeline to handle the data quality issues:
- Lemmatization using spaCy's transformer-based model (en_core_web_trf) to normalize the varied terminology and slang
- Bigram and trigram phrase detection with Gensim's Phrases model to capture multi-word expressions describing effects and characteristics
- Part-of-speech filtering retaining only nouns and adjectives to focus analysis on substantive descriptive content
- Document-term matrix construction with CountVectorizer using stopword removal and maximum document frequency threshold of 0.8
Model Selection and Evaluation
Experimented with 2, 3, and 4-topic models to identify the configuration that produced the most interpretable and distinct thematic clusters. Evaluated each model qualitatively based on topic coherence, thematic separation, and alignment with the researchers' domain knowledge of herbal remedy classifications.
Presented the different topic structures to the research team and recommended the 4-topic model trained with 80 passes, which produced clear separation between:
- Specific botanical varieties and preparation methods
- Energizing and uplifting therapeutic effects
- Sedative and sleep-promoting effects
- Pain relief and anxiety management applications
The researchers agreed with this assessment, confirming that the discovered topics aligned with established botanical classifications and therapeutic effect categories.
Supplemented topic modeling with TextBlob sentiment analysis, extracting polarity and subjectivity scores for each botanical preparation to quantify overall user satisfaction and the subjective nature of reported experiences.
Stakeholder Education and Communication
The research team had no prior experience with NLP or computational text analysis. Throughout the project, I explained the methodology in detail - not just what the analysis did, but why specific approaches were necessary given the data constraints. This included clarifying:
- Why short reviews required aggregation rather than individual analysis
- How topic modeling discovers latent themes versus simple keyword matching
- What the model outputs represented and how to interpret topic weights
- The limitations and assumptions of the analytical approach
This educational component was essential for the researchers to understand both the capabilities and limitations of the analysis, ensuring they could accurately represent the methodology in their eventual publication.
Deliverables and Outcomes
Consulted with the research team to understand their analytical workflow and software requirements. They used JMP for statistical analysis, so I structured the deliverables to integrate with their existing tools:
- Comprehensive report documenting the methodology, findings, and limitations
- CSV files containing topic assignments and sentiment scores for each botanical preparation, formatted for direct import into JMP
- Detailed explanation of data structure and recommended approaches for downstream statistical analysis
The analysis enabled the research team to proceed with their publication. The topic structure and sentiment scores provided the quantitative foundation they needed to characterize therapeutic effects across different botanical varieties, supporting research that would not have been possible without NLP analysis of the review corpus.
Development Environment
- Python
- Jupyter Notebook
- spaCy (en_core_web_trf)
- Gensim (LDA, Phrases, Phraser)
- scikit-learn (CountVectorizer)
- TextBlob
- NLTK
- Pandas
- NumPy
- Matplotlib
- Seaborn
- pyLDAvis